How to Fix Poor Data Quality in Healthcare AI Projects
Imagine an AI model trained to detect early-stage sepsis one of medicine’s most time-sensitive emergencies. It achieves 94% accuracy in the lab. Then it’s deployed. Within weeks, clinicians stop trusting it. Why? Because 23% of the input lab values were pulling from legacy EHR fields populated inconsistently across three hospital sites. The model was never the problem. The data was.
This scenario isn’t hypothetical. It’s the defining failure mode of healthcare AI in 2025. While healthcare organizations pour billions into AI transformation strategy, the ROI keeps underperforming and poor data quality is overwhelmingly to blame.
- 80% of healthcare AI projects cite data quality as their top barrier to deployment
- $3.5T estimated annual cost of poor data quality across U.S. healthcare alone
- 60% of trained healthcare AI models fail to generalize beyond their source institution
- 4x higher model retraining costs when data quality issues are caught post-deployment
This post is a practical field guide for clinical informatics teams, data engineers, and AI leads who are done diagnosing the problem and ready to fix it with modern tooling, real-world use cases, and an opinionated strategy for getting it right the first time.
Why healthcare data is uniquely broken
Healthcare data sits at the intersection of every data quality nightmare: legacy infrastructure, regulatory pressure, high-stakes labeling, and siloed systems that were never designed to interoperate. Before you can fix data quality, you need to understand precisely where it breaks down.

- Interoperability gaps: HL7 v2, FHIR R4, and proprietary EHR schemas coexist in the same organization and clash silently during data pipelines.
- Label inconsistency: Clinician annotations for the same condition vary by site, specialty, and even time of day, creating noisy ground truth for supervised models.
- Missing & sparse data: Missingness in healthcare is rarely random patients who miss follow-ups are systematically different, biasing imputation strategies.
- Temporal drift: Coding practices, device firmware, and clinical workflows change over time, causing silent model degradation that’s easy to miss.
- Privacy constraints: HIPAA and emerging state-level privacy laws restrict what data can be centralized, shared, or used for training without complex governance layers.
- Demographic bias: Training datasets over-represent insured, urban, and English-speaking populations producing models that fail on the patients who need AI most.
Key insight
Data quality issues in healthcare aren’t primarily a technical problem they’re an organizational and process problem that requires technical solutions. The fix starts with governance, not code.
Emerging technologies solving the problem
The good news: a convergence of new tools and architectural patterns have made high-quality healthcare AI data pipelines far more achievable. Here’s what’s actually working at scale.
- FHIR-native data lake houses: Platforms like Databricks on Azure Healthcare APIs and AWS Health Lake now allow teams to ingest raw EHR data and query it in standardized FHIR R4 format without manual ETL transforms. This eliminates one of the most error-prone steps in healthcare data pipelines.
- LLM-powered data curation: Large language models are now being used to extract structured clinical data from free-text notes, reconcile conflicting ICD-10 codes, and flag labeling inconsistencies tasks that previously required thousands of clinician hours.
- Federated learning frameworks: Tools like NVIDIA FLARE and PySyft enable model training across distributed hospital datasets without centralizing sensitive patient data, dramatically expanding training set diversity while maintaining privacy.
- Synthetic data generation: Generative models (particularly GANs and diffusion models fine-tuned on clinical data) can now produce synthetic patient records that preserve statistical distributions and are provably de-identified allowing safe augmentation of sparse cohorts.
- Data observability platforms: Monte Carlo, Great Expectations, and Soda Core now offer healthcare-specific rule templates for automated data profiling, anomaly detection, and pipeline monitoring, enabling continuous quality enforcement rather than point-in-time audits.
- OMOP CDM standardization: The OHDSI Observational Medical Outcomes Partnership Common Data Model (OMOP CDM) has become the de facto standard for multi-site healthcare AI research, enabling reproducible, network-scale studies with consistent vocabularies.
Step-by-step: fixing data quality in your healthcare AI project
The following framework is sequenced deliberately. Teams that skip to step 3 or 4 without completing the earlier steps consistently struggle with recurring quality issues. Invest in the foundation first.
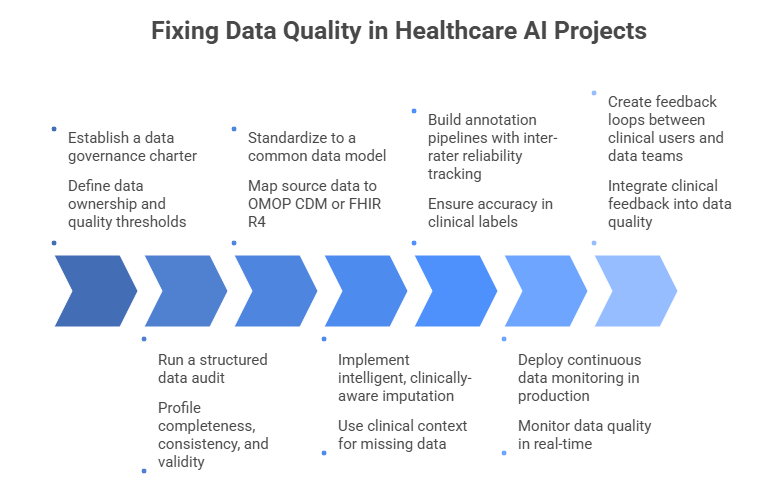
Establish a data governance charter before writing any pipelines
Define data ownership, stewardship roles, acceptable quality thresholds (per field, per model), and escalation paths for anomalies. Assign a clinical data steward someone who understands both the clinical semantics and the engineering context to every major data domain. Without this, technical fixes drift without accountability.
Run a structured data audit across every source system
Profile completeness, consistency, timeliness, and validity for every field in your feature set. Use automated tools like Great Expectations or Soda Core to generate a baseline quality scorecard. Prioritize fields with high feature importance in your models a 10% missingness rate in a low-importance field is far less dangerous than 3% in a critical one.
Standardize to a common data model (CDM)
Map all source data to OMOP CDM or FHIR R4 before any downstream use. This forces you to confront semantic mismatches early when they’re cheap to fix rather than during model debugging. Tools like Usagi (OMOP) and HAPI FHIR Server make the mapping process auditable and repeatable. Your data engineering solutions team should own this layer permanently, not as a one-time project.
Implement intelligent, clinically-aware imputation
Avoid mean/median imputation for clinical variables missingness often encodes clinical signal (a lab not ordered is clinically different from a lab that was ordered and lost). Use multiple imputation with clinical context features, or indicator variables for missingness where appropriate. Validate imputation strategies against complete-case subsets before applying broadly.
Build annotation pipelines with inter-rater reliability tracking
For supervised learning tasks requiring clinical labels, implement structured annotation workflows with at least two independent annotators for a calibration set. Track Cohen’s Kappa or Fleiss’ Kappa per label type. Retire annotators whose agreement scores fall below threshold. Platforms like Scale AI Health and Labelbox now offer HIPAA-compliant annotation environments with built-in reliability metrics.
Deploy continuous data monitoring in production
Data quality is not a pre-deployment problem only. Implement runtime checks for distribution shift, feature drift, and upstream schema changes. Set automated alerts for when input data quality falls below thresholds that would compromise model reliability. Treat data SLAs with the same rigor as model SLAs they’re inseparable.
Create feedback loops between clinical users and data teams
Clinicians interacting with AI outputs are your best source of real-world data quality signals. Build structured feedback mechanisms into your model interfaces even simple thumbs-down with a reason code. Route flagged predictions to data quality reviews, not just model retraining queues. The best healthcare AI solutions treat clinical feedback as a first-class data quality signal.
Best practices and expert recommendations
- Version your datasets like code: Use DVC or Delta Lake to track dataset versions alongside model versions. When a model degrades, you need to know if the data changed.
- Don’t impute blindly: Always consult a clinical domain expert before deciding how to handle missingness. The right answer is rarely statistical it’s clinical.
- Test for bias proactively: Stratify performance metrics by age, sex, race, and insurance status before deployment. Aggregate accuracy hides dangerous subgroup failures.
- Standardize before you scale: Resist the urge to add more data sources before standardizing existing ones. More bad data is worse than less good data.
- Make quality visible: Build a data quality dashboard that’s accessible to both clinical and engineering stakeholders. Shared visibility drives shared accountability.
- Separate training from production data: Production EHR data changes constantly. Treat your training dataset as a versioned artifact don’t retrain on live data without an explicit pipeline.
For organizations at the beginning of their AI transformation journey, investing in dedicated AI consulting services that specialize in healthcare data architecture can compress years of trial and error into months. The decisions made in the first 90 days of a healthcare AI data program shape its trajectory for years.
Common mistakes and how to avoid them
- Treating data quality as a pre-project task, not an ongoing discipline.Data quality is a continuous operational function not a checkbox you complete before model training begins. Assign ongoing ownership, budget, and tooling accordingly.
- Relying on single-site data for multi-site deployment.A model trained on one institution’s data distribution will almost always underperform when deployed elsewhere. Plan for multi-site validation from day one, even if training data is initially single-site.
- Conflating data completeness with data quality.A field can be 100% complete and still be systematically wrong. Completeness is necessary but not sufficient validity, consistency, and clinical plausibility must also be assessed.
- Ignoring temporal structure in time-series clinical data.Standard train/test splits applied to time-series EHR data cause data leakage. Always split on time boundaries, not random patient indices.
- Under-investing in clinical annotation quality.Cheap crowdsourced labeling has no place in high-stakes healthcare AI. The cost of poor annotation quality compounds through every downstream model iteration.
- Failing to monitor for concept drift post-deployment.Clinical practice changes new drug approvals, updated protocols, EMR upgrades all shift the data distribution your model was trained on. Monitor continuously and retrain on a defined cadence.
What's next: the future of healthcare data quality
The frontier of healthcare data quality is moving toward automation, federation, and intelligence. Here’s what to expect in the next 24–36 months.
- AI-native data quality: The next generation of machine learning development frameworks will embed data quality evaluation directly into the model training loop automatically flagging problematic training examples, detecting annotation errors, and recommending remediation steps without human intervention.
- Regulatory pressure as a quality driver: The FDA’s evolving guidance on AI/ML-based Software as a Medical Device (SaMD) is moving toward mandatory data quality documentation as part of regulatory submissions. Organizations that build quality infrastructure now will have a significant compliance advantage.
- Universal patient data graphs: Emerging health data platforms are moving toward longitudinal patient data graphs that unify claims, clinical, genomic, and social determinants data with semantic consistency creating a foundation for AI that’s far richer and more reliable than anything possible with siloed EHR data today.
- Privacy-enhancing computation at scale: Federated learning, differential privacy, and secure multi-party computation are rapidly maturing from research tools to production infrastructure enabling collaborative AI development across competing health systems that was previously legally and technically impossible.
Strategic outlook
Organizations that invest in healthcare data quality infrastructure today aren’t just improving current AI projects they’re building the foundation for AI capabilities that don’t yet exist. The competitive moat in healthcare AI will belong to whoever has the cleanest, most comprehensive, most trusted data.
How App Maisters can help
At App Maisters, we specialize in end-to-end healthcare AI data strategy from FHIR-native data architecture and OMOP CDM implementation to production-grade ML pipelines and continuous data quality monitoring. We understand that the hardest problems in healthcare AI aren’t model problems they’re data problems.
Our team of clinical informatics experts, data engineers, and AI architects has helped health systems, payers, and digital health companies across North America turn fragmented, low-quality data environments into reliable AI foundations. Whether you’re navigating AI adoption challenges in healthcare or ready to accelerate your AI ROI in healthcare, we bring both the technical depth and the healthcare domain expertise to get it right.
FAQs
What causes poor data quality in healthcare AI projects?
Poor data quality in healthcare AI is caused by inconsistent EHR systems, missing clinical data, and interoperability gaps. App Maisters helps organizations address these issues through structured data governance and standardized architectures.
How can healthcare organizations improve AI data quality?
Healthcare organizations can improve AI data quality by implementing data governance frameworks, standardizing datasets, and using data observability tools. App Maisters provides end-to-end solutions to streamline this process.
Why does healthcare AI fail to deliver accurate results?
Healthcare AI often fails due to biased datasets, incomplete patient records, and data drift over time. App Maisters focuses on building reliable data pipelines that ensure consistent and accurate AI performance.
What is the role of data governance in healthcare AI?
Data governance ensures data accuracy, consistency, and compliance in healthcare AI projects. App Maisters helps establish strong governance frameworks to improve AI outcomes and reduce risks.
How does poor EHR data impact AI models in healthcare?
Poor EHR data leads to unreliable predictions, reduced clinician trust, and failed AI deployments. App Maisters specializes in transforming fragmented EHR data into high-quality, AI-ready datasets.
What tools are used to fix healthcare data quality issues?
Tools like FHIR-based platforms, data observability systems, and AI-driven data curation tools help fix data quality issues. App Maisters integrates these modern technologies into scalable healthcare AI solutions.
How can App Maisters help with healthcare AI data challenges?
App Maisters helps healthcare organizations overcome AI data challenges by building robust data pipelines, ensuring compliance, and optimizing data for better AI ROI.


















